
Catégories
- Solutions de manutention simples et ergonomiques
- Solution de confort et de recyclage au quotidien
- Panneaux d'affichage configurables et ses accessoires
- Tableaux Totems Multifaces : 3, 4 5 ou 6 faces rotatifs magnétiques sur roulettes
- Porte documents
- Bandes magnétiques
- Marquage par rubans adhésifs ou pochoirs
- Séquenceur, lanceur Kanban et tableau FIFO
- Signalétique : Panneaux et Plaques de porte
- Jeux pédagogiques Lean
- Goodies lean et Lean-6sigma
- Sécurité des biens et des personnes
- Outils Animation Lean
- Sur-mesure



Les statistiques inférentielles
Les statistiques inférentielles visent à décrire une population à partir d’un échantillon et donc de réaliser des « inférences ».
Introduction
Les statistiques inférentielles sont un ensemble d'outils qui permettent de décrire une population à partir d'un échantillon et de réaliser des inférences à partir de ces données. Contrairement aux statistiques descriptives qui se contentent de décrire les caractéristiques d'un échantillon, les statistiques inférentielles visent à déduire des comportements généraux à partir d'observations particulières ou d'autres séries de données. Le choix des outils statistiques à utiliser dépend des objectifs de l'étude, du type de données disponibles et des lois de distributions pertinentes. En utilisant ces méthodes, il devient possible d'extrapoler les conclusions tirées d'un échantillon à une population plus large, fournissant ainsi une base solide pour la prise de décision et l'élaboration de stratégies.
1. Calculer l’échantillon
Première étape, calculer la taille de l’échantillon à recueillir pour assurer une bonne représentativité de la population.
2. Effectuer le prélèvement
Le recueil des données doit se faire selon un protocole prédéterminé adapter au contexte et objectif de l’étude.
3. Calculer les caractéristiques
On calcule les différents coefficients liés aux statistiques descriptives : paramètre du milieu, variance et étendu. Ceci permet d’avoir une idée des données recueillis et des indications sur les perspectives de l’étude.
4. Identifier la loi de distribution des données
Quel que soit l’objectif de l’étude, la loi de distribution des données est un élément essentiel qui va guider le choix des outils statistiques. Il est nécessaire de :
- Mettre en place un graphique de distribution
- Interpréter le résultat à priori
- Mettre en place un test d’ajustement
- Déduire la loi de distribution
5. Analyser les données en fonction de votre objectif
Estimer une proportion, un écart-type ou une moyenne d’une population
On souhaite estimer la moyenne, l’écart-type ou la proportion d'une population à partir d'un échantillon représentatif. Par exemple, si nous constatons qu'un échantillon donné présente 10% de défauts, nous souhaitons savoir quelle est cette proportion au sein de l'ensemble de la population. Pour répondre à cette question, nous utilisons une estimation par intervalle de confiance.
Comparer des groupes de données de variables identiques
Il est souvent nécessaire de comparer différentes populations qui partagent une même variable. Cette situation se présente notamment lorsque nous souhaitons évaluer l'efficacité d'une action ou d'une amélioration. Nous comparons les données avant et après ces changements pour déterminer si les résultats sont significatifs. Pour cela, nous utilisons des tests d'hypothèses.
Etudier les corrélations et/ou prédire les comportements entre des groupes de données de variables différentes
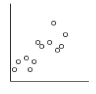
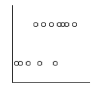
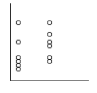
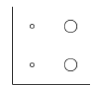
On souhaite comparer des données pour comprendre des relations de causes à effet. On cherche ainsi à étudier l’influence d’une ou plusieurs variables sur une ou plusieurs autres et mettre en place un modèle qui permet de prédire le comportement de celle-ci. On utilise différents outils en fonction du type de données :
| Variable expliquée Y | |||
|---|---|---|---|
| Quantitative continue et discrète | Quantitative nominale et ordinale | ||
Variable explicative X | Quantitative continue ou discrète | Étude de régression
Exemple : X : diamètre d'un arbre Y : hauteur d'un arbre | Étude de régression
Exemple : X : taille Y : couleur des cheveux |
| Qualitative | Test d'hypothèses ou étude de régression
Exemple : X : traitement pharmacologique Y : taux de globules blancs | Test d'hypothèses
Exemple : X : port de la ceinture de sécurité Y : gravité des blessures | |
6. Effectuer l’étude
Pour la suite, il suffit de suivre le processus de déroulement de l’outil choisi.
7. Calculer la significativité et conclure
Quels que soient l’outil statistique utilisé et le type d’étude, le rôle du statisticien est de s’assurer que le résultat obtenu est significativement viable. Autrement dit,
Est-ce que le résultat obtenu est-il réel ou seulement dû au hasard ?
Pour cela, on utilise un test d’hypothèses.
Source
1 – C. P. Dancey, J. reidy (2007) – Statistiques sans maths pour psychologues
J. P. Oriol (2007) – Formation à la statistique par la pratique d’enquêtes par questionnaires et simulation
A. Baccini (2010) – Statistique descriptive élémentaire
T. Lorino (2005) – Probabilités et statistique
S. Robin (2007) – Régression linéaire simple