
Catégories
- Solutions de manutention simples et ergonomiques
- Solution de confort et de recyclage au quotidien
- Panneaux d'affichage configurables et ses accessoires
- Tableaux Totems Multifaces : 3, 4 5 ou 6 faces rotatifs magnétiques sur roulettes
- Porte documents
- Bandes magnétiques
- Marquage par rubans adhésifs ou pochoirs
- Séquenceur, lanceur Kanban et tableau FIFO
- Signalétique : Panneaux et Plaques de porte
- Jeux pédagogiques Lean
- Goodies lean et Lean-6sigma
- Sécurité des biens et des personnes
- Outils Animation Lean
- Sur-mesure



1 – Les études de régression
Les régressions permettent de valider une corrélation tout en permettant d’identifier l’équation qui relie les données et ainsi de prédire les comportements.
Introduction
Les études de régression sont des méthodes mathématiques utilisées pour analyser le comportement des variables entre elles. Elles permettent de déterminer la relation fonctionnelle entre différentes variables et de quantifier l'intensité de cette relation. En étudiant les corrélations entre les variables, les régressions facilitent la prédiction des comportements futurs. Ces analyses peuvent être utilisées dans divers objectifs, tels que l'établissement d'indicateurs pertinents pour évaluer des processus, en choisissant des variables plus accessibles à mesurer tout en ayant un lien significatif avec le résultat recherché
Les régressions ne peuvent être utilisées que lorsque la ou les données explicatives sont quantitatives (continue ou discrète) et selon le tableau suivant :
| Variable expliquée | |||
| Quantitative continue ou discrète | Qualitative (attribut) | ||
Nb de variables explicatives quantitatives (continue ou discrète) On peut également prendre des variables qualitatives à condition de les transformer en variables dichotomiques ou en classe. Exemple : Homme et Femme sont traduits en 0 et 1 | Une variable | Régression simple ou monotone | Régression logistique |
| Plusieurs variables | Régression multiple | Régression logistique | |
Historique
L'expression de “régression” trouve ses racines dans le travail du mathématicien Francis Galton (1822 - 1911), qui était le cousin de Charles Darwin. En se penchant sur la transmission des caractères héréditaires, Galton observa que bien que les parents de taille élevée avaient tendance à avoir des enfants de grande taille, et vice versa, la taille moyenne des enfants avait une tendance à se rapprocher de la taille moyenne de l'ensemble de la population. En d'autres termes, les enfants nés de parents extrêmement grands ou petits tendaient à se rapprocher de la taille moyenne générale.
C'est son ami Karl Pearson qui, plus tard, a confirmé cette loi universelle de régression en collectant des données sur plus d'un millier de tailles auprès de groupes de familles. Pearson découvrit que la taille moyenne des fils de pères de grande taille était inférieure à celle de leurs pères, tandis que la taille moyenne des fils de pères de petite taille était supérieure à la taille de leurs pères, entraînant ainsi un "rapprochement" des fils de taille extrême vers la taille moyenne.
1. Recueillir les données
La récolte des données constitue la première étape dans une étude de régression. Pour mener une analyse de régression, les variables explicatives doivent être des variables quantitatives, excluant ainsi les données de type oui/non ou blanc/bleu. Si les données d'origine ne sont pas quantitatives, il est possible de les transformer en variables quantitatives, si cela est faisable et pertinent pour l'étude.
Prenons l'exemple d'un contrôle qualité lié aux traces sur une étiquette. Initialement, ce contrôle est effectué en utilisant une évaluation binaire : bon ou pas bon. Toutefois, pour une étude de régression, on peut traduire l'apparition des traces par une mesure de leur taille. Ainsi, une absence de trace serait représentée par la valeur 0, tandis que la présence d'une trace serait mesurée en termes de surface, constituant ainsi une variable quantitative.
Par ailleurs, comme pour toute étude statistique rigoureuse, il est essentiel de respecter les règles de base lors de la collecte des données. Cela inclut notamment la suppression des valeurs aberrantes, si nécessaire, pour éviter qu'elles biaisent les résultats.
De plus, il est important de s'assurer que le même nombre de données est recueilli pour chacune des deux variables impliquées dans l'analyse de régression.
Enfin, il est impératif de vérifier que les valeurs recueillies sont indépendantes les unes des autres. Pour cette vérification, deux approches courantes sont la logique ou l'utilisation du test de Durbin Watson.
2. Identifier le type de régression
Selon le schéma présenté en introduction, on sélectionne le type de régression à mettre en place en fonction du type de données.
3. Caractériser la relation
Lors de cette étape, on représente graphiquement les données afin d'identifier à priori la nature de la relation entre la variable à expliquer et chaque variable explicative. Que l'on opte pour une régression simple ou multiple, ces graphiques mettent en évidence la variation de la valeur à expliquer en fonction d'une seule des autres valeurs explicatives à la fois. Ainsi, plusieurs graphiques sont élaborés, chacun montrant la corrélation entre la variable cible et une variable explicative spécifique.
Les résidus sont les différences entre les valeurs prédites par notre modèle de régression et les données réelles. Pour trouver la meilleure régression possible, l'objectif est de minimiser la somme des carrés des résidus. En d'autres termes, la régression la plus performante est celle qui permet de réduire au maximum les écarts entre les valeurs prédites et les données réelles.
Nous allons retrouver 3 types de relations:
| Type de liaison | Description | Graphique |
| Liaison linéaire | Cas le plus simple, les deux variables présentent une corrélation qui peut être montante ou descendante. | 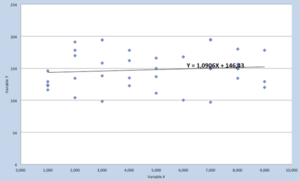 |
| Liaison monotone | Cas plus complexe, la liaison n’est pas linéaire mais est soit strictement positive ou strictement négative. | 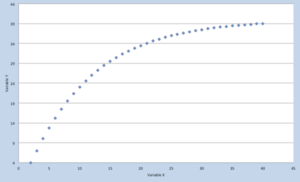 |
| Liaison non monotone | On retrouve une « rupture » dans la liaison mais nous pouvons mathématiquement la représenter. | 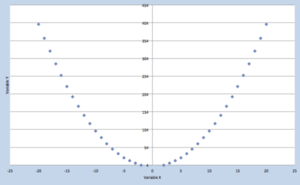 |
4. Quantifier l’intensité de la corrélation
On quantifie l’intensité de la corrélation. Pour cela, il existe trois différents coefficients que nous décrivons ci-dessous et qui sont à utiliser en fonction du tableau ci-dessous.
Le coefficient de Bravais-Pearson – r
Le coefficient de Bravais-Pearson est un indicateur mesurant la co-variation entre deux variables. Il évalue le degré de corrélation en calculant le rapport entre la variation commune aux deux mesures et la variation maximale possible entre elles. Ce coefficient est exprimé par la formule suivante :
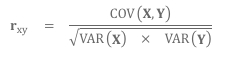
Il est important de noter que ce coefficient est valide lorsque nous disposons d'au moins 30 données. Si notre échantillon est plus petit, nous utiliserons le Coefficient de Pearson ajusté.
En élevant la valeur de r², on obtient le coefficient de détermination, qui représente la quantité de variance partagée entre les deux échantillons. Exprimé en pourcentage, plus ce coefficient se rapproche de 100%, plus notre modèle de régression explique de manière satisfaisante les données étudiées.
Toutefois, ce coefficient est sensible aux valeurs aberrantes. Il se pourrait que le coefficient de Pearson soit faible uniquement parce que une ou plusieurs valeurs ne rentrent pas dans le modèle qui pour autant est bon. Pour vérifier, on calcule le coefficient de Spearman ou de Kendall. Moins sensible à ce type de valeurs, ils permettent de dire s’il y a bien une relation malgré que le coefficient de Pearson soit faible.
Autocorrélation
Dans le cas particulier où nous avons une série chronologique d’une même donnée, on pourra calculer via le coefficient de Bravais Pearson ce que l’on appelle dans ce cas l’Autocorrélation. Celui-ci nous permet donc de savoir si dans le temps, notre donnée suit une même tendance ou non.
Le coefficient de Spearman – ρ
Fondamentalement, le coefficient de Spearman est un cas particulier du coefficient de Pearson. Il se base sur le calcul de la différence des rangs. C’est donc un test non paramétrique.
Le tau de Kendall – τ
Le Tau de Kendall est également un test non paramétrique. Il se base sur la différence des rangs des variables.
Interprétation
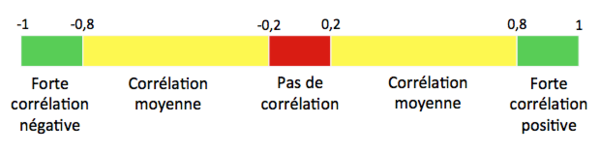
Dans les 3 cas, les valeurs des coefficients oscillent entre -1 et 1 et s’interprètent selon le schéma suivant :
5. Valider la significativité de l’étude
Il est nécessaire de valider si les résultats obtenus ont un sens ou non. Le détail des tests étant mis dans les différents articles relatifs aux régressions linéaires, multiples…, nous ne mettons ci-dessous que la liste :
- Un test sur le r2 du modèle
- Un test sur la pente du modèle
- Le calcul d’intervalle de confiance de la pente du modèle
- Le calcul de la p-Value
- Le calcul de coefficient de corrélation partielle pour identifier si d’autres facteurs sont à inclure dans le modèle
Source
1 – F. Galton (1886) – Family likeness in stature
2 – K. Pearson (1903) – On the laws of inheritance
K. Pearson (1896) – Mathematical contributions to the theory of evolution
C. E. Spearman (1904) – The proof and measurement of association between two things
R. Rakotomalala (2012) – Analyse de corrélation
N. Gujarati, (2003) – Basics econometric